





Abstract
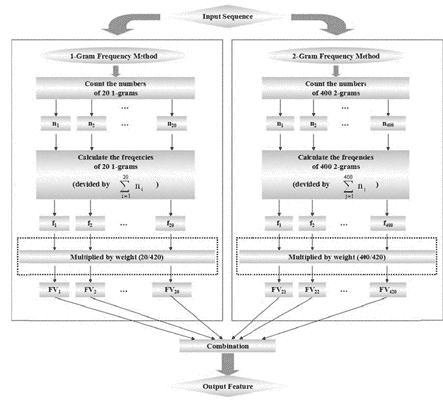
Recent developments in bioinformatics have highlighted the importance of protein structure prediction for which information about structure classes forms the foundation and plays an important role in the prediction of protein folds and tertiary structure. The majority of previous researches have focused on only four protein classes in the Structure Classification of Proteins (SCOP) database. In this paper, we focused mainly on finding the best performing prediction method using SCOP—extended (SCOPe, Release 2.03; previously known as version 1.75C in SCOP), which contains seven major protein classes, including all-α proteins, all-β proteins, α/β proteins, α+β proteins, multi-domain proteins, membrane and cell surface proteins and peptides, and small proteins. The framework that we developed consists of two stages: in the first stage we used a hybrid frequency method for feature extraction from a SCOPe dataset, and in the second stage, we calculated an effective parameter (number of trees) for the Random Forest Classifier. Our computational results on the SCOPe dataset demonstrate the efficiency and effectiveness of our model that generated predictions with an accuracy of 88%, which is much higher than the accuracies reported in previous studies. These encouraging results may be helpful for future research on protein structure and protein fold prediction. Our codes are available in http://datamining.xmu.edu.cn/~zhaoxuewei/PSP.
Keywords: Classifier, n-gram feature, Protein class, Protein structure prediction, random forests, SCOP dataset.
Graphical Abstract
Call for Papers in Thematic Issues
Mass spectrometry data acquisition and analysis for proteomics
The Thematic Issue on "Mass spectrometry data acquisition and analysis for proteomics" aims to explore the latest advancements and challenges in the field of proteomics through the lens of mass spectrometry. Proteomics, the large-scale study of proteins and their functions, plays a crucial role in understanding various biological processes and ...read more
Peptides: State-of-Art and Commercialisation Hurdles
The Editors of the Current Proteomics (CP) journal are highly privileged to welcome scientists to submit their scientific research and review articles to be considered for publication in the upcoming thematic issue. The topics should cover various aspects of peptides in regard to their synthetic methodologies, formulation approaches, pharmacological challenges, ...read more
Related Journals

Current Bioactive Compounds

Combinatorial Chemistry & High Throughput Screening

Current Diabetes Reviews
Current Enzyme Inhibition

Current Molecular Medicine

Current Medicinal Chemistry

Current Pharmaceutical Biotechnology

Current Topics in Medicinal Chemistry

Current Protein & Peptide Science

Medicinal Chemistry
Related Books

Research Methodology and Project Management in Biotechnology

Recent Progress in Pharmaceutical Nanobiotechnology: A Medical Perspective

Recent Trends In Livestock Innovative Technologies

Algal Biotechnology for Fuel Applications

Terpenoids: Recent Advances in Extraction, Biochemistry and Biotechnology

Recent Advances in Biotechnology
 21
21